A misunderstanding about convolution in deep learning
The definition of convolution in deep learning is somehow different from that in math or engineering.
Check this blog http://www.songho.ca/dsp/convolution/convolution2d_example.html
By this definition, before doing element wise product and traversing, we have to flip the kernel. However, it doesn’t work like this in deep learning.
Let’s do an experiment in Pytorch.
First, define a function to help us specify the kernel.
1 | import torch |
1 | def new_conv2d_with_kernel(kernel: torch.tensor, **kwargs) -> nn.Conv2d: |
see the outcomes.
1 | new_conv2d_with_kernel(torch.tensor([[1,1], [0, 0]], dtype=torch.float)).weight |
Parameter containing:
tensor([[[[1., 1.],
[0., 0.]]]], requires_grad=True)
So, lets try an example
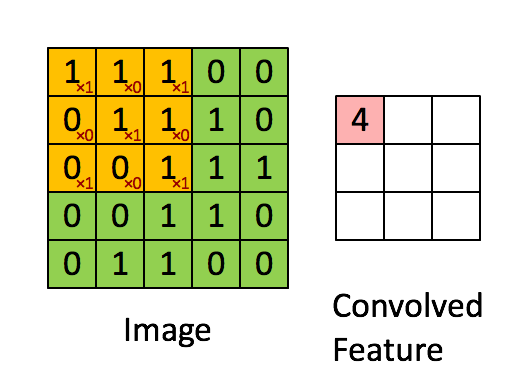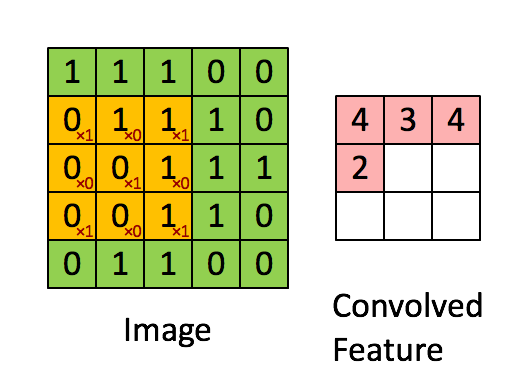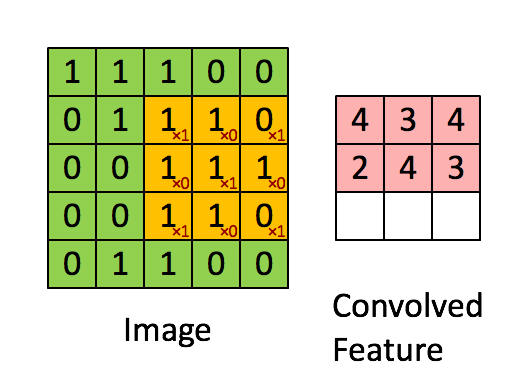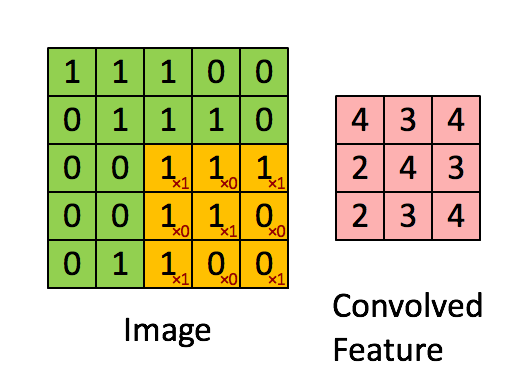
1 | input = torch.tensor([ |
tensor([[[[4.0062, 3.0062, 4.0062],
[2.0062, 4.0062, 3.0062],
[2.0062, 3.0062, 4.0062]]]], grad_fn=<ConvolutionBackward0>)
Let’s try another example in a mathematical background.
http://www.songho.ca/dsp/convolution/convolution2d_example.html
1 | input = torch.arange(1, 10).reshape(3, 3).type(torch.float) |
tensor([[[[ 13.0968, 20.0968, 17.0968],
[ 18.0968, 24.0968, 18.0968],
[-12.9032, -19.9032, -16.9032]]]], grad_fn=<ConvolutionBackward0>)
The output is different from the example in this blog.
Try what gonna happen if we flip the kernel. (flipping should happen on each axis!)
1 | flipped_kernel = torch.tensor([ |
tensor([[[[-12.7119, -19.7119, -16.7119],
[-17.7119, -23.7119, -17.7119],
[ 13.2881, 20.2881, 17.2881]]]], grad_fn=<ConvolutionBackward0>)
This time the output matches the example. And you can check this post to see the consequence of misusing.
Conclusion
Concepts in different subjects may share the same name but with different definitions. Be careful with that.